


[Formers]大语言模型是如何发展到被prompting就可以完成NLP任务的,prompt到底是什么?

本条读书笔记以从pretraining谈起,简要介绍LLM从GPT-1, BERT, BART, 到GPT-2的发展,并配合简述我最喜欢的NLP研究员Timo Schick(Toolfomer的作者)的三篇prompt-based learning的文章简要介绍prompt的演变历程。
Pretraining
Pretraining最早应用在CV领域,如ImageNet。 思想是通过预训练,使得深度神经网络习得某类型数据(视觉或文字)普遍性的feature,然后运用到下游的不同类型的任务,节省下游任务训练数据和模型enginnering的开销。
彼时,在NLP领域,因为语言本身的时序特征,流行范式是针对不同的NLP任务,设计不同的RNN网络,因而需要搭建模型的专家能力才能完成NLP任务。 这种能力的门槛加上RNN天然对算力的不友好,客观上限制了NLP的发展和pretraining的表现。
Transformer的诞生给了NLP发展pretraining方向的机会,随后出现的GPT-1,采用了transformer decoder的架构进行预训练。
Language Modeling
具体来说,GPT采用 ‘接话茬’ 的方式进行预训练。
比如,给出‘秋刀鱼的滋味,猫跟你都想了__’,训练模型接话茬 ‘解’。
通过大语料训练,GPT拥有了超强的接话茬能力。

同年,BERT(transformer encodes)出现了。
它diss GPT只能捕捉一句话从左到右的context,所以它提出了一种Bidirectional的预训练方式, 即完形填空。
比如,给出‘秋刀鱼的滋味,[mask] 跟你都想了解’,训练模型完形填空 ‘猫’。
BERT具有对文本有超强的整体把握能力,因而屠榜NLU任务。
此后,预训练风靡一时,除了单纯的transformer encoders 或decoders,encoder+decoder的架构也被拿来做预训练,比如BART 和T5.

Prompt-based Learning
此时NLP范式变为pretraining+fintune,即拿一个训好的gpt或者BERT, 用具体的labelled data进行整体微调模型参数,完成下游任务。 但随着语言模型越来越大,这种fintune依然需要一定量级的fintue data,似乎并没有充分地挖掘预训练的知识。 于是就产生了下一个范式,即prompt-based learning。
Prompt-based learning的核心思想是把下游任务转回到language modeling,代表人物就是toolformer的作者Timo. 之前做过toolformer的读书笔记,感兴趣的读者可以去看。
Paper 1: PET Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
当我们判断‘best pizza ever‘的sentiment时,在传统fintune方法中,需要带有标注positive和negative的数据训练。
如果转回到language modeling问题: best pizza ever!it is [mask].
语言模型应该可以靠预训练获得的完形填空能力,把[mask]替换为一个possitive的词汇,如‘good’
而 best pizza ever!it is [mask] 就是一个prompt。
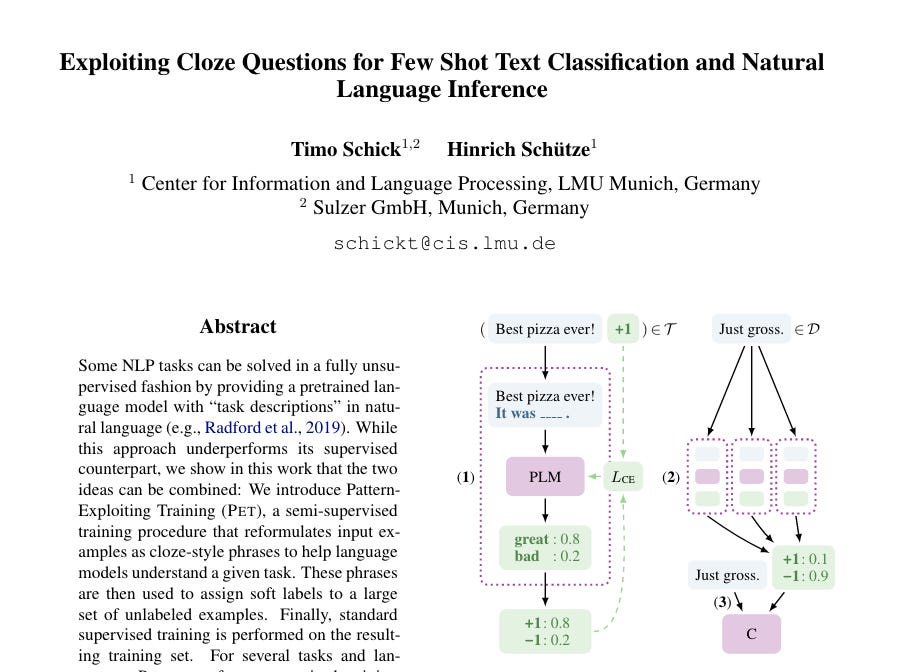
由此可以明白,prompt就是让语言模型挖掘自身能力的提示词,进一步说,语言模型就是靠它预训练时的language modeling完成自身知识的挖掘。
Paper 2: GenPET Few-Shot Text Generation with Natural Language Instructions
上面的例子是一个简单的classification的task,那么prompt-based learing可以做文字生成的任务么,答案也是肯定的。
如做summarization,传统方法中,我们需要原文和总结的数据来fintune模型。
但 Summary: __ [TEXT],就可以把引导语言模型完成总结任务,把空白处填上总结。

Summary: __ [TEXT] 就是一个prompt。
由此可见,prompt不紧可以引导语言模型输出单个单词替换[Mask] token,还可以将空白的token替换为需要的内容。 而统一地,运用的都是language modeling的方法。
值得注意的是,上述两篇paper仍然需要一些训练数据来做finetune,跟现在的in-context learning的few-shot还是有一定区别。
回到预训练的发展,语言模型进化到了GPT-2 具体来说,GPT-2探讨了,经过language modeling后的语言模型,不仅可以根据input,输出output
p ( output | input )
也具有multi-task的能力,即根据task和input,输出output
p ( output | input, task )

对应Timo的文章,按照用户的输入,生成dataset 对应的prompt为:
Task: Write two sentences that [Instruct]. Sentence 1: “x1”
Sentence 2: “

再次总结,prompt是激发语言模型按照language modeling的方式挖掘预训练知识的提示词,随着模型越来越大,预训练知识越来越多,prompt变得愈加重要。
本条读书笔记,只探讨了prompt在gpt-2前的发展阶段,跟如今的prompt还有一定的区别,但旧一点的prompt似乎更让我们懂得它的原理。
东锡学长你好,我是现在在乌普萨拉就读language technology的学生,目前也在做prompt-learning方向的毕设,因为没有找到一个私信的入口,所以就在这里评论哈哈,想请教您一些关于自己现在这个毕设的问题。我现在在用OpenPrompt的框架来做一个对某对话型数据进行文本分类的任务,用GPT-2这样的模型确实能做到few-shot(3%的全量数据)就能有60%左右的acc,相比之前全量数据fine-tune模型85%,3%数据fine-tune大概20%的acc来讲肯定有进步。但后面就陷入了改OpenPrompt不同Component的情况,比如做数据的预处理/改改Template/换模型/换一种找verblaizer里面label words的方法/换few-shot sampling的方法等等。东改西改,也没有更多的acc提升。
有三个问题想请教您,一是您觉得这种情况(中小模型,不冻结模型的prompt-tuning)有其他什么trick是您看论文时觉得很有用,可以尝试的idea呢?二是您觉得写thesis怎么组织比较好呢?目前比较粗糙的想法是template一节,verbalizer一节,模型一节,数据一节等等,每节分别写改变这个component的实验。但是总感觉每一节的实验的motivation有点浅,没什么贡献(比如template可能就是换几句话而已,感觉很炼丹)三是现在写thesis,公司的老板希望我加入一些现在大模型,model frozen的In-context learning方法,比较追前沿一点,但是学校的导师觉得这个方向已经超出我毕设论文的scope了,觉得没办法写进thesis。您是怎么看的呢?不知道是不是有些太伸手党,总之非常感谢!